
{kind=link}
Extracción de relaciones a partir de descripciones no estructuradas de especies utilizando TaxonNERD y Llama2 - 7B
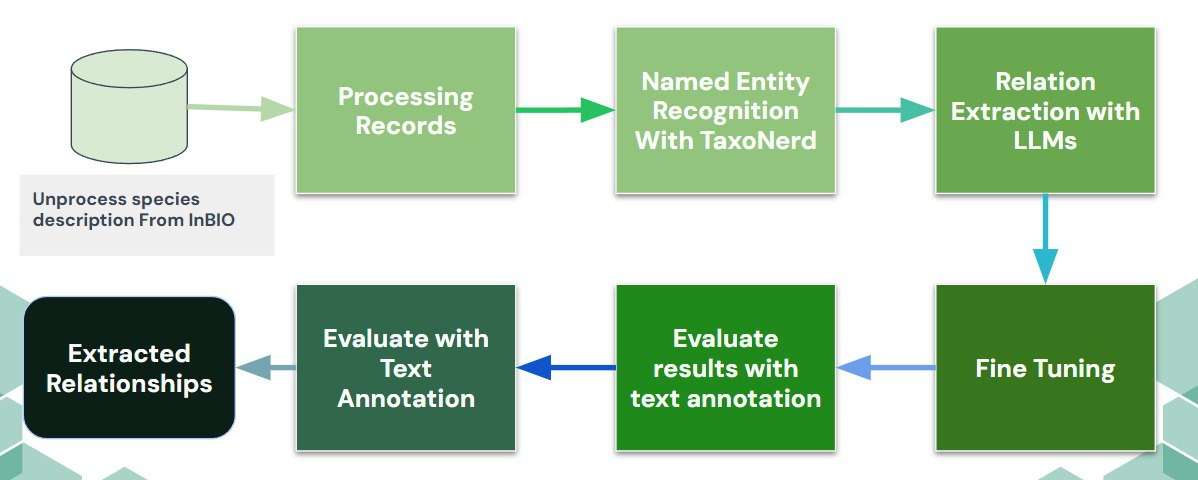
Este proyecto explora cómo extraer información estructurada sobre relaciones alimentarias entre especies animales a partir de descripciones textuales originalmente desorganizadas. En el proyecto se combinan ontologías ecológicas con métodos avanzados de Procesamiento del Lenguaje Natural (NLP), utilizando herramientas especializadas como TaxoNERD para el reconocimiento de entidades, y el modelo LLaMA2-7b para la extracción de relaciones específicas, particularmente dinámicas de presa-depredador. El conjunto de datos utilizado proviene del Instituto Nacional de Biodiversidad (INBio), con descripciones en español e inglés sobre hábitos alimenticios y comportamientos ecológicos.
La metodología consistió en preprocesar los textos del INBio para identificar entidades taxonómicas y términos relacionados con la alimentación mediante TaxoNERD. Posteriormente, se empleó el modelo LLaMA2-7b para extraer relaciones concretas, generando así un conjunto estructurado de datos donde se detalla claramente la dieta de cada especie estudiada. Los resultados obtenidos fueron revisados manualmente mediante una herramienta personalizada de anotación textual desarrollada específicamente para este proyecto, asegurando la calidad y precisión de la información generada.
La evaluación mostró resultados prometedores, con una precisión del 68%, un recall del 73% y un F1-score del 71%, destacando especialmente la capacidad del modelo para detectar relaciones clave en las descripciones de las especies. Como siguiente paso, se planea refinar aún más el modelo para mejorar su precisión y ampliar el alcance a otras relaciones ecológicas, fortaleciendo así su utilidad para futuras investigaciones en biodiversidad y esfuerzos de conservación ambiental.
Simulador de Ecosistemas utilizando Modelos Grandes de Lenguaje (LLM).
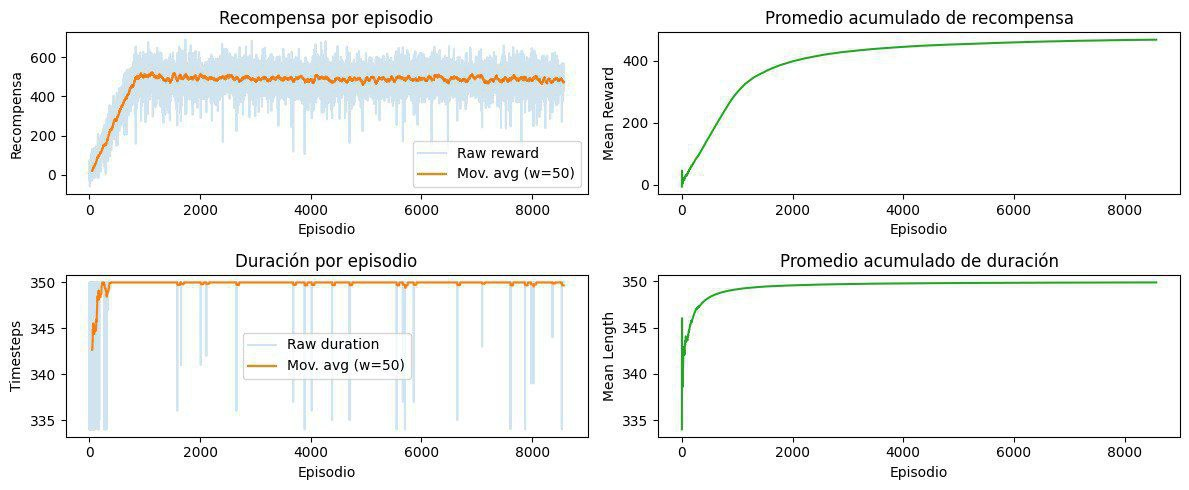
Este proyecto busca desarrollar un simulador de ecosistemas que permita modelar la interacción entre múltiples agentes, recursos y el entorno, utilizando aprendizaje por refuerzo profundo (Deep Reinforcement Learning) combinado con modelos avanzados de lenguaje natural (LLM). Inicialmente, se implementará un entorno simplificado en 2D utilizando la biblioteca Gym de Python, en el cual diversos agentes aprenderán estrategias óptimas de supervivencia mediante algoritmos como DQN, PPO y A2C. Además, se incorporarán capacidades avanzadas de razonamiento e interacción mediante el uso de un modelo LLM (como LLaMA 3), facilitando la toma de decisiones inteligentes, comunicación natural entre agentes y generando explicaciones comprensibles de sus acciones.
Posteriormente, se evaluará la posibilidad de escalar el simulador a un entorno tridimensional utilizando Minecraft junto con la biblioteca MineRL, explorando la viabilidad técnica y documentando posibles limitaciones o desafíos. Durante el desarrollo se elaborarán varios productos entregables, incluyendo un repositorio de código completo, informes técnicos sobre la arquitectura y algoritmos empleados, así como demostraciones visuales del funcionamiento de los agentes en ambos entornos (2D y 3D).
Finalmente, este proyecto pretende ofrecer no solo un ambiente de simulación versátil y rico en interacciones biológicas, sino también una plataforma robusta para investigar comportamientos emergentes en sistemas multiagente y explorar aplicaciones innovadoras de inteligencia artificial y procesamiento de lenguaje natural. El simulador permitirá estudios más profundos sobre dinámicas ecológicas, facilitando además futuras investigaciones en la integración práctica y efectiva entre aprendizaje por refuerzo profundo y modelos generativos de lenguaje avanzado.